コラム
製造業におけるAI活用検討の第一歩
【第3回】製造業・プロセス業における画像判別AI活用の検討ポイント[後編]
2019年4月
画像検品の種類
前回の判断に従い、自社の業務が「AIによる画像検品が向いている業務」だったとしましょう。
次に考えるのは、「どんなAIで実現するか」です。
画像検品において、AIには、大きく2つのタイプが存在します。
1つ目は、AIに「どんな状態が良品か」「どんな状態が不良品か」を全て覚えこませる「教師あり学習」、
2つ目は、AIに「どんな状態が良品か」のみを覚えこませる「one-class分類(半教師あり学習)」です。
教師あり学習
「教師あり学習」は、機械学習の中でも、最も一般的といえる手法です。
動作は、図5のように、「学習」と「予測・分類」の2ステップに分かれます。
この過程は、人間で言えば「試験勉強(学習)」と「試験本番(予測・分類)」の関係を思い浮かべて頂ければ、理解しやすいと思います。
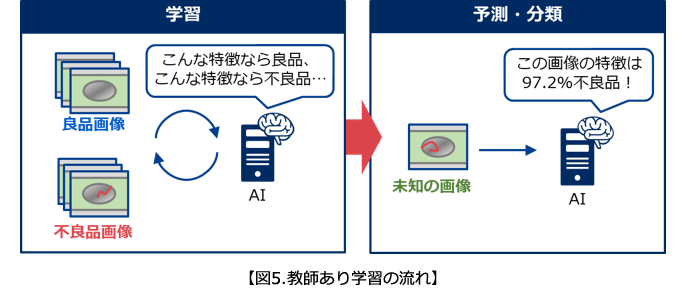
基本的には、AIは、学習させる画像枚数が多ければ多いほど、判別精度が良くなります。
そのため、自社の製品が少品種多量生産で、日々ある程度の不良品が出ているような場合、良品・不良品、双方の画像が集めやすく、精度を高めやすいと考えられます。
一方で問題となるのは、多品種少量生産の場合、または歩留まりが極端に良い場合です。
教師あり学習では、分類したいカテゴリごと(図5の場合、良品・不良品それぞれ)に、最低1,000枚程度の画像が必要になります。
この場合、1製品あたり、1,000枚の不良画像を集めるとしても、数年がかかりになってしまうということもあり、「教師あり学習」を用いた画像検品は難しくなってしまいます。
そのような場合に検討したいのが、「one-class分類(半教師あり学習)」です。
one-class分類(半教師あり学習)
こちらも、「学習」と「予測・分類」の2ステップに分かれるのは、先ほどの図5と同様です。
異なるのは、学習時に「良品画像」のみをAIに与え、予測・分類時は「これまで覚えていた特徴と異なる画像かどうか」のみを判断する点です。(図6)
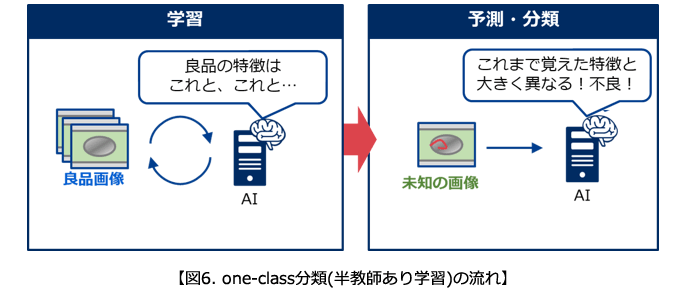
「one-class分類」であれば、多品種少量生産(または歩留まりが極端に良い場合)でも、十分なデータを準備し易くなります。
また、予め「これが不良」とは教えないことで、「未知の不良を発見できる」という利点もあります。
では、全て「one-class分類」で事足りるかというと、そうでもありません。
「不良の発生タイプはほぼ全て既知」である場合は、「one-class分類」に比べ、「教師あり学習」の方が、より高い精度で検知できます。
また、「不良と判別した中でも、どのタイプの不良だったか分類したい」といった場合、「教師あり学習」でないと、対応は難しくなります。
ほかにも、それぞれ表7のように、様々なメリット・デメリットがあります。
少品種多量生産か?複数タイプに分類したいか?未知の不良に対応したいか?など、現状の業務や、AI導入後のイメージを具体的にして、検討しましょう。※1
※1 今回挙げたのは、あくまで代表的な例です。
判断が難しい場合や、どちらのメリットも得たい場合、2タイプのどちらにもあてはまらない場合など、様々な技術や対処方法が存在します。

全体の検討ステップ
これまで、AIに関する理解を交えつつ、「そもそも画像判別AIに向いている業務か」「その業務にどんな手法を使うべきか」についてご説明してきました。
最後に、業務への導入後までのプロセスを紹介します。(図7)
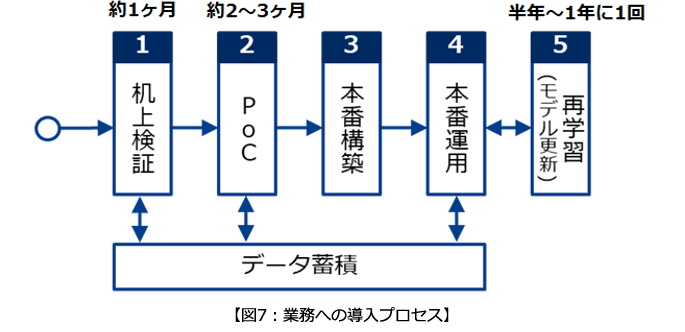
導入プロセスに関わるAI技術(機械学習)の主な特徴として、以下の2点が挙げられます。
どの程度の精度になるか、分析してみないと分からない
AIの精度は、学習させるデータと、学習の際の設定(パラメータ)に大きく左右されるため、過去に似たような分析を行った実績があっても、どの程度の精度になるかは、やってみるまでわかりません。 そのため、すぐに本番構築を行えば、実用精度に至らず、マテハン機器や周辺プログラムなど、多額の投資が無駄になる可能性があります。
これを解消するために、少額の投資でごく限られた範囲の分析を行い、実現可能性を確かめる作業が「1.机上検証」です。
また、実現可能性が十分だと分かれば、更にある程度の投資を行い、実際にどの程度の精度になるのかを追求する「2.PoC」を行います。
この2つの検証で実用に足る精度が得られると分かって、初めて本番構築を行うことで、時間こそかかりますが、確実な投資が可能となるのです。
また、机上検証やPoCの段階で目標精度に達しない場合、その原因として、学習する画像が不足している場合が多々あります。その場合、次第に画像を蓄積していって、データが貯まった段階で再度検証を行うこととなります。
運用を続けると精度が落ちることがある
図5,6のような学習を行うことで、画像判別ができるようになったAIのことを、学習モデルといいます。
この学習モデルは、学習時と同条件の画像に関しては、常に一定の精度で判別できます。
しかし、実運用では、同じような画像で判別していても、撮像環境のわずかな変化や、対象物の素材等のブレ・変化によって、次第に判別精度が落ちて行ってしまう場合が多々あります。
このようなケースに対応するため、「5.再学習(学習モデルの再作成)」を行う必要があります。
これを定期的に行うことで、環境の変化に対応でき、業務上十分な精度で判別を行い続けることができます。
また、この作業を行うことで、運用中に撮像・蓄積された画像を用いて、以前よりも更に精度を高められる可能性もあります。
ここまで、製造業・プロセス業における画像判別AI活用の検討ポイントをご紹介してきました。画像判別AIの検討を行うことで、これまでよりも具体的な検討イメージを掴んで頂ければ幸いです。
次回からは、需要予測についてご紹介したいと思います。

※分かり易さを優先するため、表記に一部曖昧な点や、不正確な点が含まれる場合があります。ご了承ください。
資料ダウンロードはこちらから

ご質問・ご相談などお気軽にどうぞ
